Predictive Insights
AI For Predictive Insights - Predict Incidents, Reduce Outages. Act Before Impact!

cfxCloud Data-centric AIOps now available on AWS Marketplace
Powered by Robotic Data Automation Fabric (RDAF)
IT Problems Persist Inspite of Multiple Monitoring Tools
Traditional monitoring tools are reactive in nature and cannot prevent IT service problems and business impact.
Traditional monitoring approaches are typically reactive in nature. They rely on alerts from monitoring tools about breaches pertaining to localized performance data, which falls short in modern environments which demands prevention of issues rather than reacting to them. Incidents captured in ITSM systems also tend to mirror alerts and In majority of cases they are opened by impacted users as trouble tickets or service desk requests, which is after the fact and hurts IT service reliability and SLA.
Challenges

Unable to predict or foresee broader service issues

Alerts/Incidents are reactive in nature

Alert/Incident data limited to localized performance breaches

Alerts defined mostly on statically defined thresholds

Complex IT service dependencies

Correlated metrics behavior not captured by traditional tools
43% of companies that suffered a catastrophic loss of data and IT capability went out of business immediately
51% of companies that suffered a catastrophic loss of data and IT capability went out of business within 2 years.
[ Source: Gartner and Others ]Average revenue loss for one hr downtime - $127,000 USD
Meet CloudFabrix Stack Watch
CloudFabrix Solution combines traditional monitoring tools/methods and apply AI/ML technologies to help IT teams prevent issues before they occur
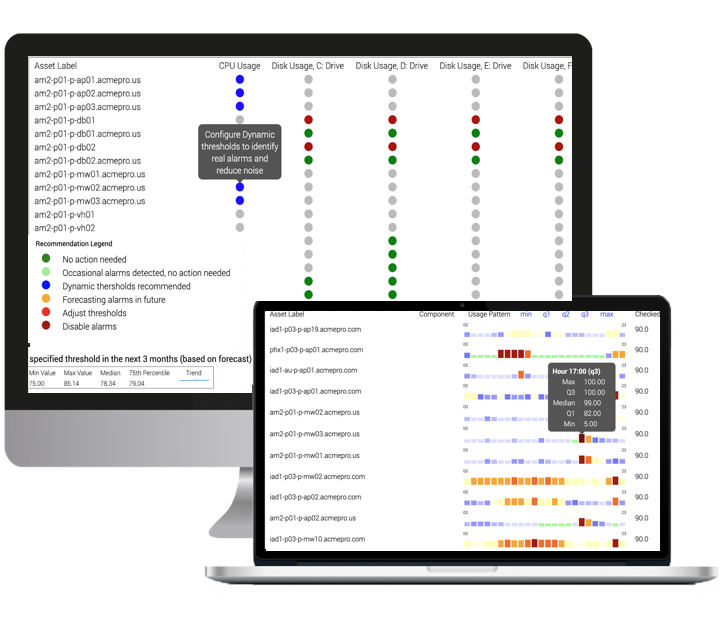
Define your technology stack or use the recommended ones and then let the solution guide you towards achieving higher reliability of that stack with predictive/ proactive insights


Near real-time proactive monitoring capability

Self learning of leading indicators for observation

Observe leading indicators for anomalies

Correlate health metrics across stack

Improved stack reliability and SLA compliance

Data driven design for easy configuration

Flexibility in defining stacks and outcomes

Scale ready with enterprise grade security
How it Works?
Stack definition, proactive observation of key leading indicators and insights for preemptive actions

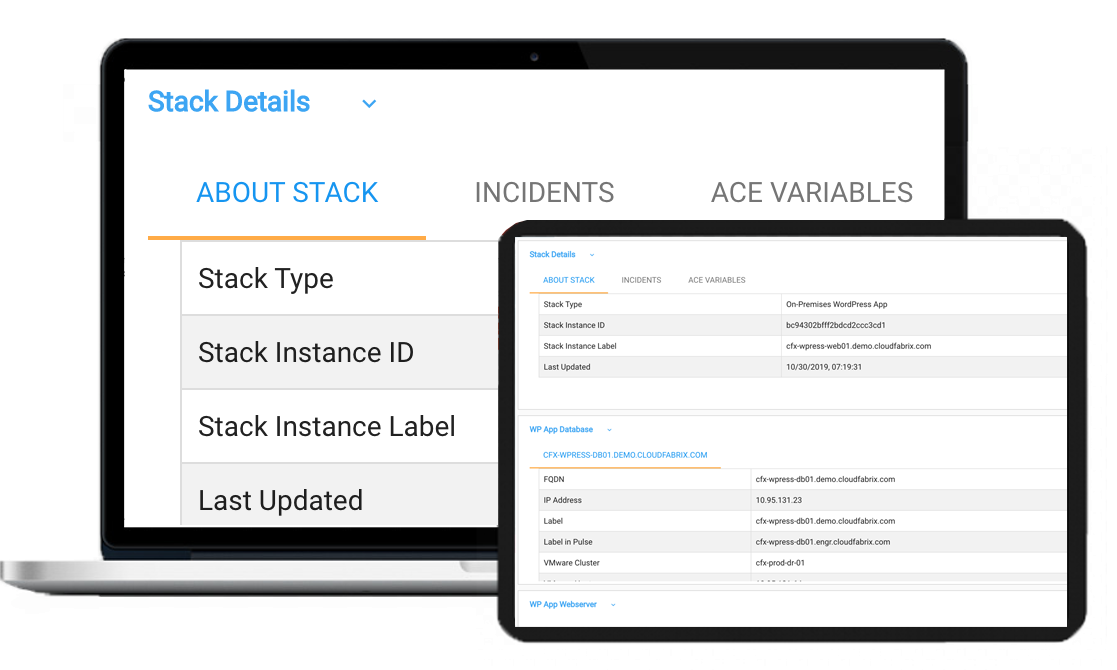
Stack Definition
Stack is a logical composition of technology elements that deliver a set of outcomes
- User can define their own stack
- Choose system resolved stacks for services
- Can include both application and infra components
- User choice in stacks for proactive monitoring
- Add/delete stacks for proactive monitoring
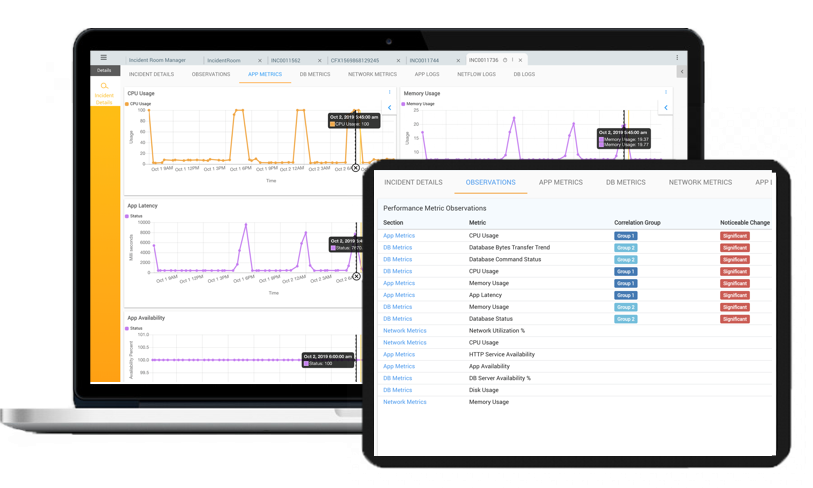
Observation for Risks
Observes metrics data, log data, security and network data related to the complete stack for potential risks
- Near real-time observation of all contextual data
- Correlate metrics across stack
- Identify and observe deviations to leading indicators
- Risk assessment using forecasting and historical patterns
Insights & Analytics
Insights and analytics for preemptive actions to avoid service outages and degradation
- Baseline and anomaly detection
- Forecasting potential future risks e.g. capacity outages etc.
- Security and lifecycle risks
- Proactive recommendations